Các config đặc biệt của Job & CronJob¶
Job và CronJob là các công cụ linh hoạt và mạnh mẽ có thể được sử dụng để lên lịch và chạy các tác vụ định kỳ. Bằng cách hiểu các config đặc biệt của Job và CronJob, chúng ta có thể sử dụng chúng để đáp ứng nhu cầu của các tác vụ cụ thể.
Restart policy¶
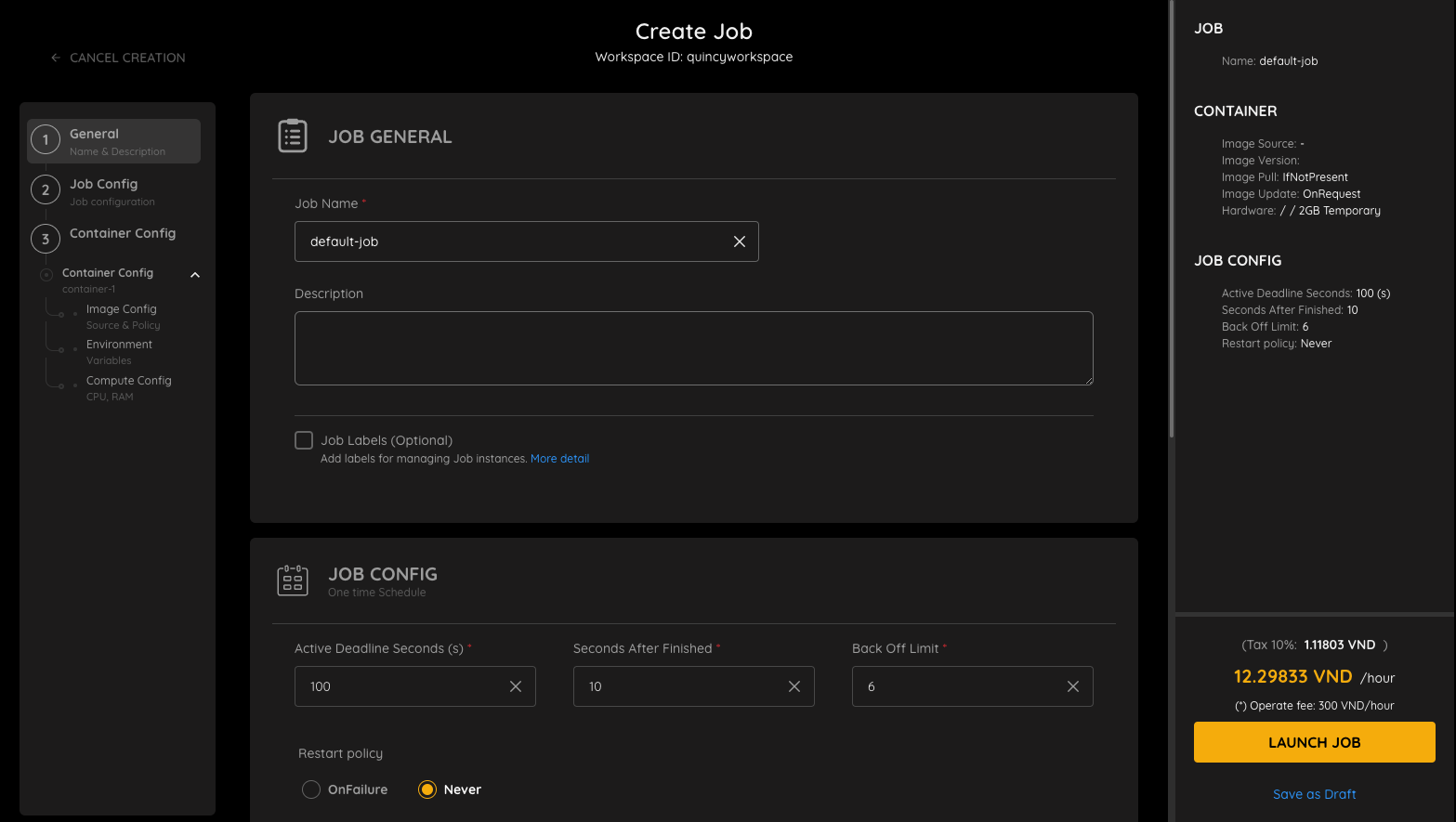
restartPolicy là một chính sách quyết định hành động của hệ thống khi một pod trong Job hoặc CronJob cần được khởi động lại. Có 3 chính sách khởi động lại chính:
OnFailure: Nếu một pod trong Job hoặc CronJob thất bại, hệ thống sẽ thử khởi động lại pod nhiều lần với khoảng thời gian tăng dần. Nếu tất cả các lần khởi động lại đều thất bại, hệ thống sẽ báo cáo lỗi và Job hoặc CronJob sẽ bị coi là thất bại.
Never: Nếu một pod trong Job hoặc CronJob kết thúc, bất kể kết quả là gì, hệ thống sẽ không khởi động lại pod. Điều này có thể hữu ích cho các Job hoặc CronJob có tác vụ chỉ cần được chạy một lần, chẳng hạn như Job tạo bản sao lưu hoặc Job cập nhật dữ liệu.
Chính sách khởi động lại mặc định của Job và CronJob là Never.
Trong ví dụ thực tế, Job sẽ thử khởi động lại pod nếu pod thất bại.
Bạn có thể lựa chọn chính sách khởi động lại phù hợp với nhu cầu của mình. Nếu bạn không chắc chắn nên sử dụng chính sách khởi động lại nào, bạn nên sử dụng chính sách mặc định là Never.
Dưới đây là một số trường hợp sử dụng của restartPolicy với Job và CronJob:
OnFailure: Bạn có thể sử dụng chính sách khởi động lại OnFailure cho các Job hoặc CronJob có tác vụ cần được chạy thành công, chẳng hạn như Job xử lý dữ liệu hoặc Job chạy các thử nghiệm.
Never: Bạn có thể sử dụng chính sách khởi động lại Never cho các Job hoặc CronJob có tác vụ chỉ cần được chạy một lần, chẳng hạn như Job tạo bản sao lưu hoặc Job cập nhật dữ liệu.
Bạn cũng có thể sử dụng restartPolicy để kiểm soát hành vi của các ứng dụng được triển khai trên hệ thống bằng cách sử dụng Job hoặc CronJob. Ví dụ, bạn có thể sử dụng restartPolicy để đảm bảo rằng một ứng dụng luôn được chạy, ngay cả khi một số thành phần của ứng dụng bị lỗi.
Active Deadline Seconds(s)¶
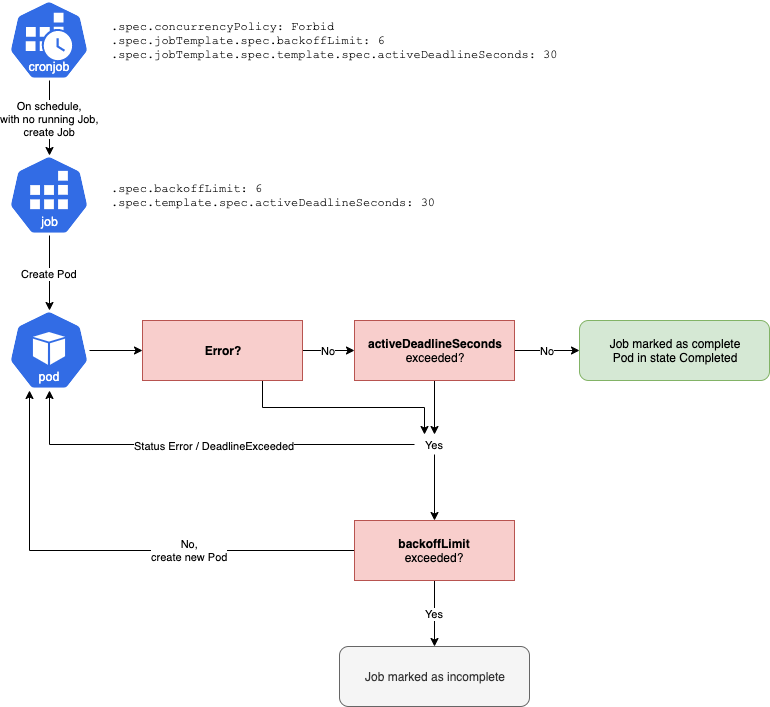
Active deadline seconds là một thông số cấu hình quan trọng trong Job và CronJob. Nó xác định khoảng thời gian tối đa mà một Pod có thể chạy trước khi bị chấm dứt. Giá trị này xác định thời gian tối đa mà Job được phép chạy. Nếu Job không hoàn thành trước thời hạn này, thì Job sẽ được coi là thất bại.
Chính sách này có giá trị mặc định của Job và CronJob là 100.
Mục đích:¶
Active deadline seconds giúp đảm bảo rằng các Jobs và CronJobs không chạy quá lâu và gây ra các vấn đề về hiệu suất hoặc tài nguyên. Nó cũng có thể được sử dụng để ngăn chặn các Jobs bị treo hoặc chạy mãi mãi.
Cách hoạt động:¶
Khi một Pod được tạo ra bởi một Job or CronJob, thời gian bắt đầu của nó được ghi lại.
Active deadline seconds được tính từ thời gian bắt đầu này.
Nếu Pod không hoàn thành công việc của nó trong khoảng thời gian này, nó sẽ bị chấm dứt.
Back Off Limit¶
backoffLimit là một trường quan trọng trong định nghĩa của công việc (Job). Trường này xác định số lần mà một công việc sẽ thử lại thực hiện nếu nó thất bại.
Khi một công việc (Job) thất bại trong quá trình thực hiện (ví dụ: một container trong công việc bị lỗi), hệ thống sẽ thử lại công việc theo số lần được đặt trong backoffLimit. Mỗi lần thử lại, hệ thống sẽ tạo một phiên bản mới của công việc và cố gắng thực hiện nó lại. Nếu công việc tiếp tục thất bại và số lần thử lại vượt quá giá trị backoffLimit, công việc sẽ bị đánh dấu là thất bại và không còn được thử lại nữa.
Giá trị mặc định của backoffLimit là 6. Giá trị min là 1. Giá trị Max là 100.
Nếu backoffLimit lớn hơn 0, công việc con sẽ thử lại tối đa số lần được xác định trước khi bị đánh dấu là thất bại.
backoffLimit quan trọng trong việc quản lý và đảm bảo tính nhất quán của các công việc. Bằng cách đặt một giới hạn, bạn có thể tránh việc công việc tiếp tục thử lại vô hạn khi gặp lỗi nghiêm trọng.
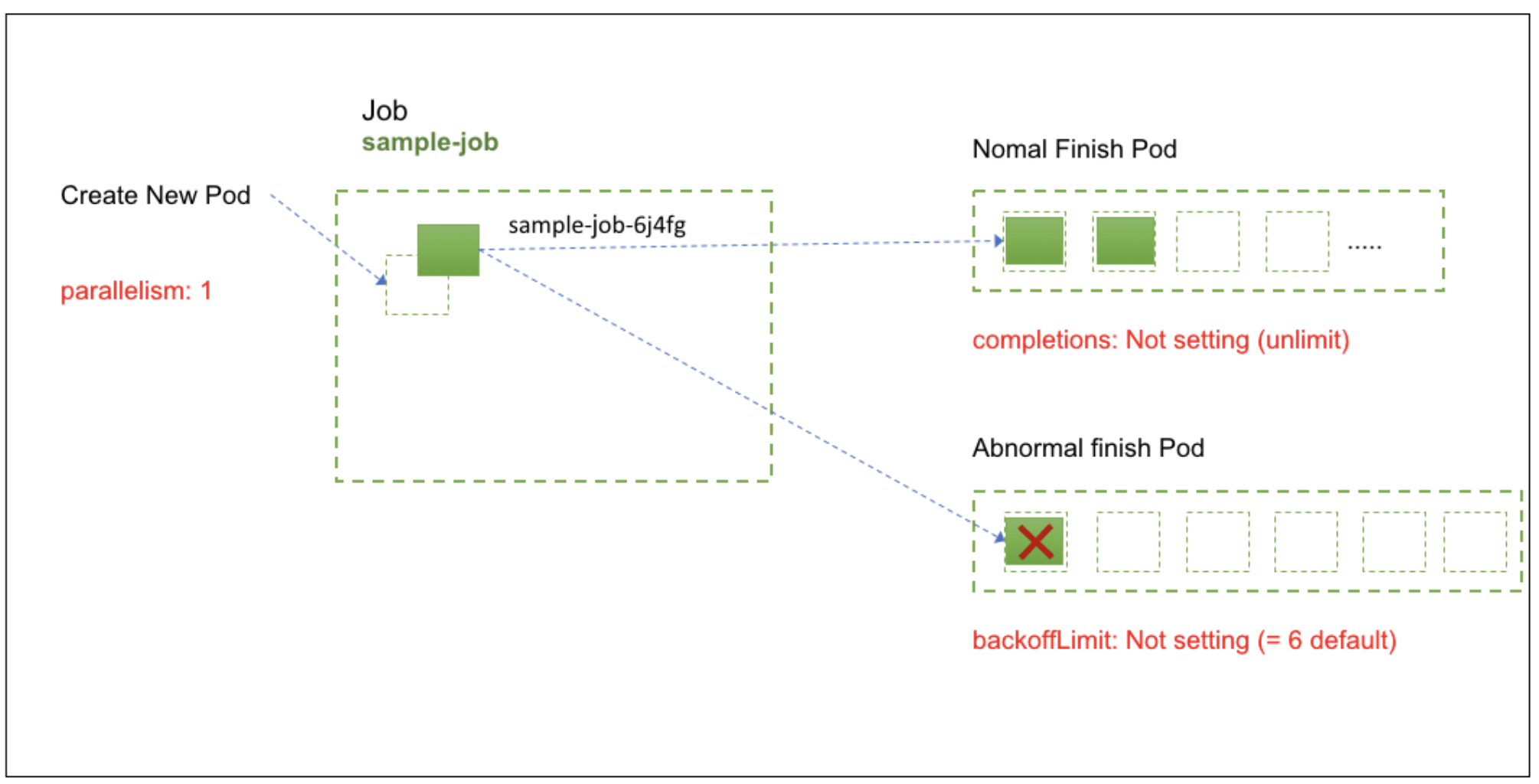
Trong ví dụ này, công việc my-job sẽ thử lại tối đa 6 lần nếu nó thất bại. Nếu nó vẫn thất bại sau 6 lần thử lại, công việc sẽ bị đánh dấu là thất bại và không còn thử lại nữa.
Giá trị lớn nhất của backoffLimit hệ thống Sunteco cho phép tối đa 100 lần. Bạn có thể đặt giá trị tùy ý cho backoffLimit trong định nghĩa của công việc (Job). Thông thường, giá trị backoffLimit được sử dụng để kiểm soát số lần thử lại của công việc sau khi thất bại. Nếu công việc vẫn thất bại sau số lần thử lại này, nó sẽ bị đánh dấu là thất bại và không còn được thử lại nữa.
Tuy nhiên, bạn nên lưu ý rằng đặt giá trị quá lớn cho backoffLimit có thể dẫn đến một số vấn đề:
Tài nguyên hệ thống: Mỗi lần thử lại của công việc sẽ tạo ra một phiên bản mới của công việc. Nếu bạn đặt backoffLimit quá lớn, điều này có thể tạo ra một số lượng lớn công việc và sử dụng tài nguyên hệ thống một cách không hiệu quả.
Thời gian: Nếu công việc vẫn thất bại sau một số lần thử lại lớn, việc đợi cho đến khi backoffLimit lớn được sử dụng có thể làm tăng thời gian để xác định rằng công việc đã thất bại cuối cùng.
Vì vậy, việc đặt giá trị backoffLimit nên được thực hiện cẩn thận và dựa trên nhu cầu cụ thể của ứng dụng và tài nguyên hệ thống. Thường thì giá trị mặc định hoặc một giá trị tương đối nhỏ như 3 hoặc 5 là phổ biến, nhưng bạn có thể điều chỉnh nó theo nhu cầu.
Starting Deadline Seconds(s)¶
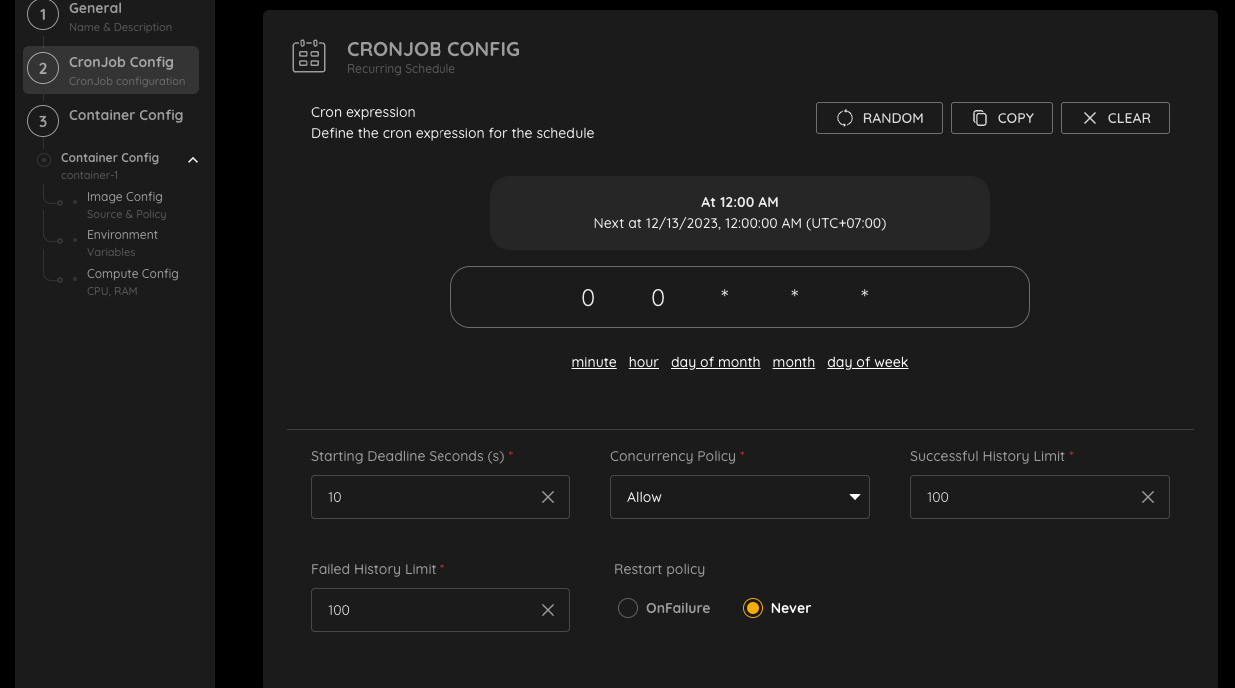
startingDeadlineSeconds là một thuộc tính của CronJob trong Kubernetes, xác định số giây mà Kubernetes sẽ chờ đợi trước khi hủy một CronJob nếu nó không thể bắt đầu. Giá trị mặc định của startingDeadlineSeconds là 0, nghĩa là Kubernetes sẽ không bao giờ hủy một CronJob do không thể bắt đầu.
Bạn có thể sử dụng startingDeadlineSeconds để ngăn chặn các Job và CronJob bị kẹt trong trạng thái “Pending” trong thời gian dài. Ví dụ, nếu bạn có một Job chạy hàng ngày vào lúc 12:00 AM và Job không thể bắt đầu vì thiếu tài nguyên, bạn có thể sử dụng startingDeadlineSeconds để hủy Job sau 30 phút.
Trong ví dụ này, công việc my-job phải bắt đầu thực hiện trong vòng 1 giờ sau khi nó được tạo. Nếu công việc không bắt đầu trong khoảng thời gian này, nó sẽ bị hủy và không tiếp tục thực hiện.
Lưu ý:
startingDeadlineSeconds là một thời gian tính bằng giây, và thời gian bắt đầu được tính từ thời điểm công việc hoặc công việc con được tạo.
Giá trị mặc định của startingDeadlineSeconds là 0, nghĩa là Kubernetes sẽ không bao giờ hủy một Job hoặc CronJob do không thể bắt đầu. Bạn có thể sử dụng startingDeadlineSeconds để ngăn chặn các Job và CronJob bị kẹt trong trạng thái “Pending” trong thời gian dài. Ví dụ, nếu bạn có một Job chạy hàng ngày vào lúc 12:00 AM và Job không thể bắt đầu vì thiếu tài nguyên, bạn có thể sử dụng startingDeadlineSeconds để hủy Job sau 30 phút.
Bạn cũng có thể sử dụng startingDeadlineSeconds để kiểm soát hành vi của các ứng dụng được triển khai trên Kubernetes bằng cách sử dụng Job hoặc CronJob. Ví dụ, bạn có thể sử dụng startingDeadlineSeconds để đảm bảo rằng một ứng dụng luôn được khởi động lại, ngay cả khi một số thành phần của ứng dụng bị lỗi.
Một số trường hợp sử dụng của startingDeadlineSeconds¶
Dưới đây là một số trường hợp sử dụng cụ thể của startingDeadlineSeconds:
Ngăn chặn các Job và CronJob bị kẹt trong trạng thái “Pending”
Bạn có thể sử dụng startingDeadlineSeconds để ngăn chặn các CronJob bị kẹt trong trạng thái “Pending” trong thời gian dài. Điều này có thể hữu ích cho các CronJob có tác vụ cần được chạy trong một khoảng thời gian nhất định.
Đảm bảo rằng một ứng dụng luôn được khởi động lại
Bạn có thể sử dụng startingDeadlineSeconds để đảm bảo rằng một ứng dụng luôn được khởi động lại, ngay cả khi một số thành phần của ứng dụng bị lỗi. Điều này có thể hữu ích cho các ứng dụng quan trọng cần được luôn hoạt động.
Kiểm soát thời gian bắt đầu của CronJob
Bạn có thể sử dụng startingDeadlineSeconds để kiểm soát thời gian bắt đầu của CronJob. Ví dụ, bạn có thể sử dụng startingDeadlineSeconds để trì hoãn thời gian bắt đầu của một Job hoặc CronJob để đảm bảo rằng nó không bắt đầu trước khi các tài nguyên cần thiết đã sẵn sàng.
Lựa chọn giá trị phù hợp¶
Khi lựa chọn giá trị cho startingDeadlineSeconds, bạn cần cân nhắc các yếu tố sau:
Thời gian cần thiết để bắt đầu CronJob
Bạn cần chọn một giá trị startingDeadlineSeconds đủ lớn để đảm bảo rằng Job hoặc CronJob có đủ thời gian để bắt đầu.
Tần suất thực hiện CronJob
Nếu Job hoặc CronJob được thực hiện thường xuyên, bạn có thể sử dụng startingDeadlineSeconds thấp hơn để đảm bảo rằng CronJob không bị hủy nhầm.
Độ quan trọng của CronJob
Nếu CronJob rất quan trọng, bạn có thể sử dụng startingDeadlineSeconds cao hơn để đảm bảo rằng CronJob luôn được khởi động lại, ngay cả khi mất nhiều thời gian để bắt đầu.
Concurrency Policy¶
concurrencyPolicy là thuộc tính của CronJob trong Kubernetes, xác định cách Kubernetes xử lý các CronJob chạy đồng thời. Có ba giá trị có thể của concurrencyPolicy:
Allow: Đây là giá trị mặc định của concurrencyPolicy, cho phép các Job hoặc CronJob chạy đồng thời.
Forbid: Giá trị này ngăn các Job hoặc CronJob chạy đồng thời. Nếu một Job hoặc CronJob mới được lên lịch khi đã có một Job hoặc CronJob có cùng tên đang chạy, Job hoặc CronJob mới sẽ bị bỏ qua.
Replace: Giá trị này sẽ hủy Job hoặc CronJob đang chạy và thay thế bằng Job hoặc CronJob mới.
Bạn có thể sử dụng concurrencyPolicy để kiểm soát cách Kubernetes xử lý các Job hoặc CronJob chạy đồng thời. Ví dụ, nếu bạn có một Job hoặc CronJob cập nhật cơ sở dữ liệu, bạn có thể sử dụng concurrencyPolicy: Forbid để đảm bảo rằng chỉ có một Job hoặc CronJob cập nhật cơ sở dữ liệu tại một thời điểm.
Bạn cũng có thể sử dụng concurrencyPolicy để kiểm soát hành vi của các ứng dụng được triển khai trên hệ thống bằng cách sử dụng Job hoặc CronJob. Ví dụ, bạn có thể sử dụng concurrencyPolicy để đảm bảo rằng một ứng dụng luôn được khởi động lại, ngay cả khi một số thành phần của ứng dụng bị lỗi.
Giá trị default của concurrency policy là Allow
Trong CronJob:¶
concurrencyPolicy có một giá trị duy nhất là Allow. Không có tùy chọn Forbid cho concurrencyPolicy trong CronJob.
Trong CronJob, nếu bạn đặt concurrencyPolicy thành Allow, nó cho phép nhiều công việc con được tạo và chạy đồng thời theo lịch trình cron. Điều này có nghĩa rằng nhiều công việc con có thể được thực hiện cùng lúc.
trong CronJob, không có tùy chọn Forbid cho concurrencyPolicy. CronJob được thiết kế để chạy các công việc con theo lịch trình cron và không đảm bảo rằng chỉ có một công việc con chạy tại một thời điểm.
Ví dụ: bạn muốn thực hiện một công việc mỗi phút nhưng công việc đó phải mất hai phút để hoàn thành thành công. Trong trường hợp này, công việc chưa được hoàn thành khi đến lúc phải thực hiện công việc tiếp theo. Nếu concurrencyPolicy được đặt thành true, công việc sẽ chạy bất kể công việc cuối cùng có được hoàn thành hay không. Nếu concurrencyPolicy được đặt thành false, công việc sẽ không chạy cho đến khi công việc cuối cùng được hoàn thành.
Một số trường hợp sử dụng của concurrencyPolicy¶
Dưới đây là một số trường hợp sử dụng cụ thể của concurrencyPolicy:
Đảm bảo rằng chỉ có một Job hoặc CronJob cập nhật cơ sở dữ liệu tại một thời điểm
Bạn có thể sử dụng concurrencyPolicy: Forbid để đảm bảo rằng chỉ có một Job hoặc CronJob cập nhật cơ sở dữ liệu tại một thời điểm. Điều này có thể giúp ngăn chặn các lỗi cơ sở dữ liệu.
Đảm bảo rằng một ứng dụng luôn được khởi động lại
Bạn có thể sử dụng concurrencyPolicy: Replace để đảm bảo rằng một ứng dụng luôn được khởi động lại, ngay cả khi một số thành phần của ứng dụng bị lỗi. Điều này có thể hữu ích cho các ứng dụng quan trọng cần được luôn hoạt động.
Ngăn chặn các Job hoặc CronJob chạy đồng thời
Bạn có thể sử dụng concurrencyPolicy: Forbid để ngăn chặn các Job hoặc CronJob chạy đồng thời. Điều này có thể hữu ích nếu bạn cần đảm bảo rằng các Job hoặc CronJob được thực hiện theo một thứ tự cụ thể.
Lựa chọn giá trị phù hợp¶
Khi lựa chọn giá trị cho concurrencyPolicy, bạn cần cân nhắc các yếu tố sau:
Loại công việc được thực hiện bởi Job hoặc CronJob
Nếu Job hoặc CronJob cập nhật cơ sở dữ liệu hoặc thực hiện các tác vụ khác có thể xung đột với nhau, bạn có thể sử dụng concurrencyPolicy: Forbid.
Tần suất thực hiện Job hoặc CronJob
Nếu Job hoặc CronJob được thực hiện thường xuyên, bạn có thể sử dụng concurrencyPolicy: Forbid để tránh quá tải tài nguyên.
Độ quan trọng của việc đảm bảo rằng Job hoặc CronJob được thực hiện
Nếu Job hoặc CronJob rất quan trọng, bạn có thể sử dụng concurrencyPolicy: Replace để đảm bảo rằng Job hoặc CronJob luôn được thực hiện, ngay cả khi một số thành phần bị lỗi.
Các trường hợp kết hợp¶
Kết hợp tùy chọn concurrencyPolicy và startingDeadlineSeconds có thể ảnh hưởng đến cách CronJob xử lý việc lịch trình mới bắt đầu khi công việc trước đó chưa hoàn thành. Dưới đây là một số trường hợp kết hợp:
Concurrency Policy: Allow, Starting Deadline Seconds: N/A (Không thiết lập)
Nếu concurrencyPolicy là “Allow” và startingDeadlineSeconds không được thiết lập (hoặc thiết lập thành nil), CronJob sẽ bắt đầu một lịch trình mới ngay lập tức khi thời gian tới theo lịch trình.
Điều này đảm bảo rằng không có sự chờ đợi nếu công việc trước đó chưa hoàn thành.
Concurrency Policy: Forbid, Starting Deadline Seconds: N/A (Không thiết lập)
Nếu concurrencyPolicy là “Forbid” và startingDeadlineSeconds không được thiết lập, lịch trình mới sẽ không bắt đầu nếu công việc trước đó chưa hoàn thành.
Lịch trình mới sẽ phải đợi cho đến khi công việc trước đó hoàn thành.
Concurrency Policy: Allow, Starting Deadline Seconds: X
Nếu concurrencyPolicy là “Allow” và startingDeadlineSeconds được thiết lập với giá trị X, CronJob sẽ bắt đầu một lịch trình mới ngay lập tức khi thời gian tới theo lịch trình, miễn là thời gian bắt đầu không vượt quá giá trị X.
Nếu thời gian tới theo lịch trình diễn ra sau thời gian X, lịch trình mới sẽ bị hủy bỏ.
Concurrency Policy: Forbid, Starting Deadline Seconds: X
Nếu concurrencyPolicy là “Forbid” và startingDeadlineSeconds được thiết lập với giá trị X, lịch trình mới sẽ không bắt đầu nếu công việc trước đó chưa hoàn thành.
Thêm vào đó, lịch trình mới sẽ bắt đầu miễn là thời gian bắt đầu không vượt quá giá trị X, sau đó nó sẽ bị hủy bỏ.
Kết hợp concurrencyPolicy và startingDeadlineSeconds cho phép bạn kiểm soát cách CronJob xử lý lịch trình mới và cách nó đối phó với công việc chưa hoàn thành và việc thực hiện lịch trình.
Failed History Limit¶
Failed history limit là một thông số cấu hình quan trọng trong CronJob. Nó xác định số Pod thất bại tối đa của một CronJob được lưu giữ trong lịch sử.
Mục đích:¶
Failed history limit giúp quản lý lịch sử của CronJob và ngăn chặn việc lưu trữ quá nhiều dữ liệu lỗi. Điều này có thể giúp cải thiện hiệu suất và giảm chi phí lưu trữ.
Cách hoạt động:¶
Mỗi lần CronJob chạy và thất bại, một Pod thất bại sẽ được tạo ra.
Số lượng Pod thất bại được lưu giữ trong lịch sử.
Khi số lượng Pod thất bại đạt đến giới hạn failed history limit, Pod thất bại cũ nhất sẽ bị xóa.
Trong ví dụ này, CronJob có failedJobsHistoryLimit là 100. Điều này có nghĩa là chỉ có 100 Pod thất bại gần đây nhất của CronJob này được lưu giữ trong lịch sử.
Những điều cần lưu ý:¶
Failed history limit chỉ áp dụng cho Pod thất bại. Pod thành công sẽ không bị xóa, ngay cả khi số lượng Pod thành công vượt quá failed history limit.
Failed history limit là một tính năng hữu ích, nhưng nên được sử dụng cẩn thận. Nếu đặt giá trị quá thấp, Pod thất bại có thể bị xóa trước khi bạn có cơ hội giải quyết vấn đề.
Successful History Limit¶
Successful history limit là một thông số cấu hình quan trọng trong CronJob. Nó xác định số Pod thành công tối đa của một CronJob được lưu giữ trong lịch sử.
Mục đích:¶
Successful history limit giúp quản lý lịch sử của CronJob và ngăn chặn việc lưu trữ quá nhiều dữ liệu thành công. Điều này có thể giúp cải thiện hiệu suất và giảm chi phí lưu trữ.
Cách hoạt động:¶
Mỗi lần CronJob chạy và thành công, một Pod thành công sẽ được tạo ra.
Số lượng Pod thành công được lưu giữ trong lịch sử.
Khi số lượng Pod thành công đạt đến giới hạn successful history limit, Pod thành công cũ nhất sẽ bị xóa.
Trong ví dụ này, CronJob có successfulJobsHistoryLimit là 3. Điều này có nghĩa là chỉ có 3 Pod thành công gần đây nhất của CronJob này được lưu giữ trong lịch sử.
Những điều cần lưu ý:¶
Successful history limit chỉ áp dụng cho Pod thành công. Pod thất bại sẽ không bị xóa, ngay cả khi số lượng Pod thất bại vượt quá successful history limit.
Successful history limit là một tính năng hữu ích, nhưng nên được sử dụng cẩn thận. Nếu đặt giá trị quá thấp, Pod thành công có thể bị xóa trước khi bạn có cơ hội sử dụng thông tin từ chúng.
Seconds After Finished¶
ttlSecondsAfterFinished: là một trường trong spec của Job. Trường này xác định số giây mà Job sẽ được giữ lại sau khi nó hoàn tất việc chạy. Nếu trường này được đặt, thì sau khi Job hoàn tất, nó sẽ bị xóa sau khi số giây trôi qua.
thường được sử dụng với CronJob và Job. Nó xác định số giây một Pod sẽ được lưu giữ sau khi hoàn thành công việc của nó.
Mục đích:¶
Giải phóng tài nguyên: Khi một Pod hoàn thành công việc của nó, nó không còn cần thiết nữa và có thể được xóa để giải phóng tài nguyên cho các Pod khác.
Quản lý lịch sử: ttlSecondsAfterFinished cho phép bạn kiểm soát khoảng thời gian Pod có sẵn để phân tích hoặc kiểm tra sau khi hoàn thành.
Cách hoạt động:¶
Khi một Pod hoàn thành công việc của nó, thời gian bắt đầu được ghi lại.
ttlSecondsAfterFinished được tính từ thời gian bắt đầu này.
Nếu Pod không bị xóa trong khoảng thời gian này, nó sẽ bị Kubernetes tự động xóa.
Trong ví dụ này, CronJob có ttlSecondsAfterFinished là 300 giây. Điều này có nghĩa là bất kỳ Pod nào được tạo ra bởi CronJob này sẽ bị xóa tự động sau 5 phút sau khi hoàn thành công việc của nó.
Những điều cần lưu ý:¶
ttlSecondsAfterFinished chỉ áp dụng cho Pod đã hoàn thành. Pod đang chạy hoặc bị lỗi sẽ không bị xóa.
ttlSecondsAfterFinished là một tính năng hữu ích, nhưng nên được sử dụng cẩn thận. Nếu đặt giá trị quá thấp, Pod có thể bị xóa trước khi bạn có cơ hội sao lưu dữ liệu hoặc kiểm tra kết quả.